How I improved my python code Performance by 371%!
How i reduced the runtime of a python script from 29 seconds to 6 seconds


Introduction
Before getting started let’s discuss the problem statement in hand. I wanted to analyze some data stored in a text file. Each row contained four numerical values delimited by a space, for a total of 46.66M rows. The size of the file is around 1.11 GB, and I am attaching a small screenshot of the data below so that you get an idea of what it looks like.
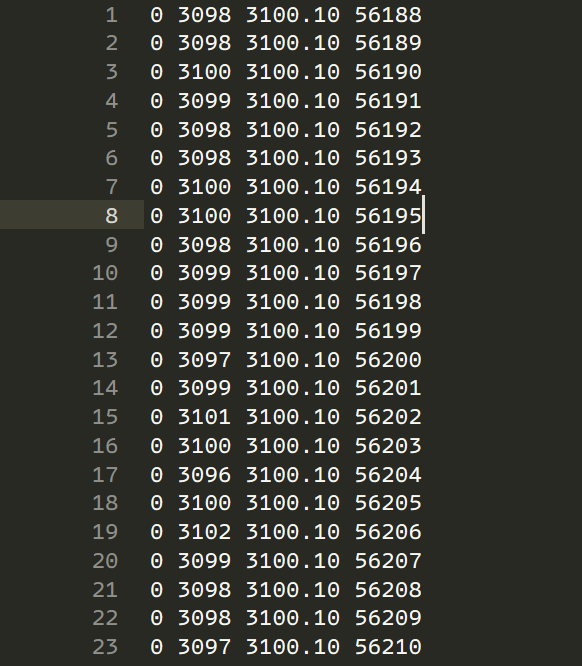
I needed to extract only the rows for a given value of the third column (3100.10 in the image above)
The first thing I tried was to simply use numpy.genfromtxt() but it gave memory error as the data was too big to handle at once.
I tried to segment the data into smaller chunks and do the same, but it was painfully slow 😫 so I tried various things to get the job done in the fastest possible way. I will show you the code along with the concepts I used to optimize my code.
Edit 1 :- Removing the f.close(), not required. I don't know why i put it in! 😕
Edit 2 :- The file only had 3100.10 and no any other value like 3100.2 or 3100.5 so converting it to integer will not select any wrong data.
Starting Point
This is the most basic approach to solving this problem. Iterate through the entire file line by line, and check if the line(row) contains that value, if it does then append the row to a new file.
def function1():
output="result.txt"
output_file=open(output, "w")
value=3100.10
with open(file, "r") as f:
for line in f:
if(line!="\n"):
if(len(line.split(" "))==4):
try:
if(int(float(line.split(" ")[2]))==int(value)):
output_file.write(line)
except ValueError:
continue
output_file.close()
The code took 29.3 s ± 56.7 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
1. Loop Invariance
The first step of optimization is to look at the code and see whether we are doing something that is not necessary at all. In the loop where I am iterating through the lines, I am using int(value) in the loop to compare the value. This can be avoided by converting the value to an int once and using it in the loop. This is called Loop invariance, where we do something in the loop again and again which can be avoided.
You can read more about this here
Here is the code!
def function2():
output="result.txt"
output_file=open(output, "w")
value=int(3100.10)
with open(file, "r") as f:
for line in f:
if(line!="\n"):
if(len(line.split(" "))==4):
try:
if(int(float(line.split(" ")[2]))==value):
output_file.write(line)
except ValueError:
continue
output_file.close()
The code took 27.5 s ± 264 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
By changing a single line of code, the code gained a 6.5% performance boost over the previous code. It's not much but this is a very common mistake that many programmers make.
2. Memory Mapping the File
It is a technique in which we load the entire file into memory (RAM) which is much faster than conventional file IO. Conventional IO uses multiple system calls to read the data from the disk and get it back to the program via multiple data buffers. Memory mapping skips these steps and copies the data to memory leading to improved performance (in most cases).
Python has a module named "mmap" that is used for thispurpose.
Here is the code!
def function3():
output="result.txt"
output_file=open(output, "wb")
value=int(3100.10)
with open(file, "r+b") as f:
mmap_file=mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
for line in iter(mmap_file.readline, b""):
if(line!=b"\n"):
if(len(line.split(b" "))==4):
try:
if(int(float(line.split(b" ")[2]))==value):
output_file.write(line)
except ValueError:
continue
mmap_file.flush()
output_file.close()
The code took 22.8 s ± 124 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
Its 20% performance increase from the previous code.
3. Using slicing instead of data type conversion
In line int(float(line.split(b" ")[2]))==value , I am slicing the row to get the 3rd element and then converting the string to float and then to int to do the comparison.
It goes like "0 3098 3100.10 56188" ->"3100.10:->3100.10->3100
Now instead of using float and then int to convert a string with a decimal to integer I used slicing which resulted in a huge performance gain as string operations are faster than data conversions.
Here is the code!
def function4():
output="result.txt"
output_file=open(output, "wb")
value=int(3100.10)
with open(file, "r+b") as f:
mmap_file=mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
for line in iter(mmap_file.readline, b""):
if(line!=b"\n"):
if(len(line.split(b" "))==4):
try:
if(int(line.split(b" ")[2][:-3])==value):
output_file.write(line)
except ValueError:
continue
mmap_file.flush()
output_file.close()
This time the code took 20 s ± 171 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
Its 14% performance increase from the previous code just by changing a line of code
4. Using the find operation
Now this is the final nail in the coffin, up until this time I was iterating through the lines, extracting the 3rd column value, and comparing it but this time I am using the find operation to look for the desired value in each line. And it is surprisingly fast!!.
You can read more about it here
Here is the code!
def function5():
output="result.txt"
output_file=open(output, "wb")
value=int(3100.10)
value=(str(value)+".").encode()
with open(file, "r+b") as f:
mmap_file=mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
for line in iter(mmap_file.readline, b""):
find=line.find(value)
if(find>=7 and find<=11):
output_file.write(line)
mmap_file.flush()
output_file.close()
This time the code took 6.22 s ± 55.8 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)
It's 221.5% performance increase from the previous code.
This is almost 4.7 times increase in performance from where we started.
Hardware Used :-
->Legion 5 15ACH6
->AMD 5800H
->16 GB RAM
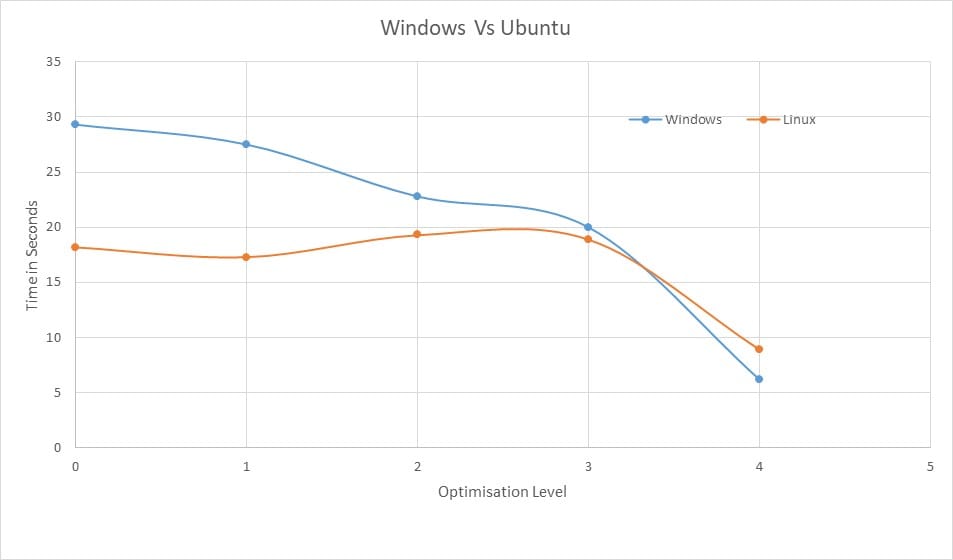
Here below you can see the comparison between Windows 10 Vs ubuntu (22.04 LTS)!
| Optimisation Level | Windows | Linux |
|---|---|---|
| 0 | 29.3 | 18.2 |
| 1 | 27.5 | 17.3 |
| 2 | 22.8 | 19.3 |
| 3 | 20 | 18.9 |
| 4 | 6.22 | 8.88 |
Thankyou for reading! :smile: